8 Cache
约 1544 个字 3 行代码 16 张图片 预计阅读时间 8 分钟
1. 缓存的作用¶
- 问题背景:处理器与内存速度不匹配(CPU 性能年增长 55%,DRAM 速度提升缓慢)。
- 例:1980 年 CPU 执行 1 条指令的时间≈DRAM 访问时间;2020 年 CPU 可执行 1000 条指令≈1 次 DRAM 访问时间。
- 解决方案:引入缓存(Cache),作为内存的快速副本 (copy),存储最近使用的数据。
- 特点:容量小、速度快、价格高,位于 CPU 芯片内。
- 大多数处理器对于 instructions 和 data 有不同的 cache
类比:图书馆写报告时,将常用书籍放在桌上(缓存),避免频繁去书库(内存)取书。

- the main memory is DRAM
- 关机时,在 disk 中的数据会被保存,但是其他的会被清除
- main memory 由 processor 直接处理;而 disk 在使用 operating system 的时候被处理
- programmer-invisible
2. 局部性原理(locality)¶
- 时间局部性:近期访问的数据很可能再次被访问。
- 例:循环变量在多次迭代中被频繁使用。
- 空间局部性:访问某个地址后,其邻近地址可能被访问。
- 例:遍历数组时,连续地址的数据会被依次加载。

以读取数据为例,首先向 cache 发送地址,(通过 tag 等方式)确认地址中的值是否在 cache 中已经有存储了。如果有(cache hit),则直接从 cache 中读取,反之 (cache miss) cache 则到 memory 中去读取 data,然后再发送给 processor
3. 缓存类型与工作机制¶

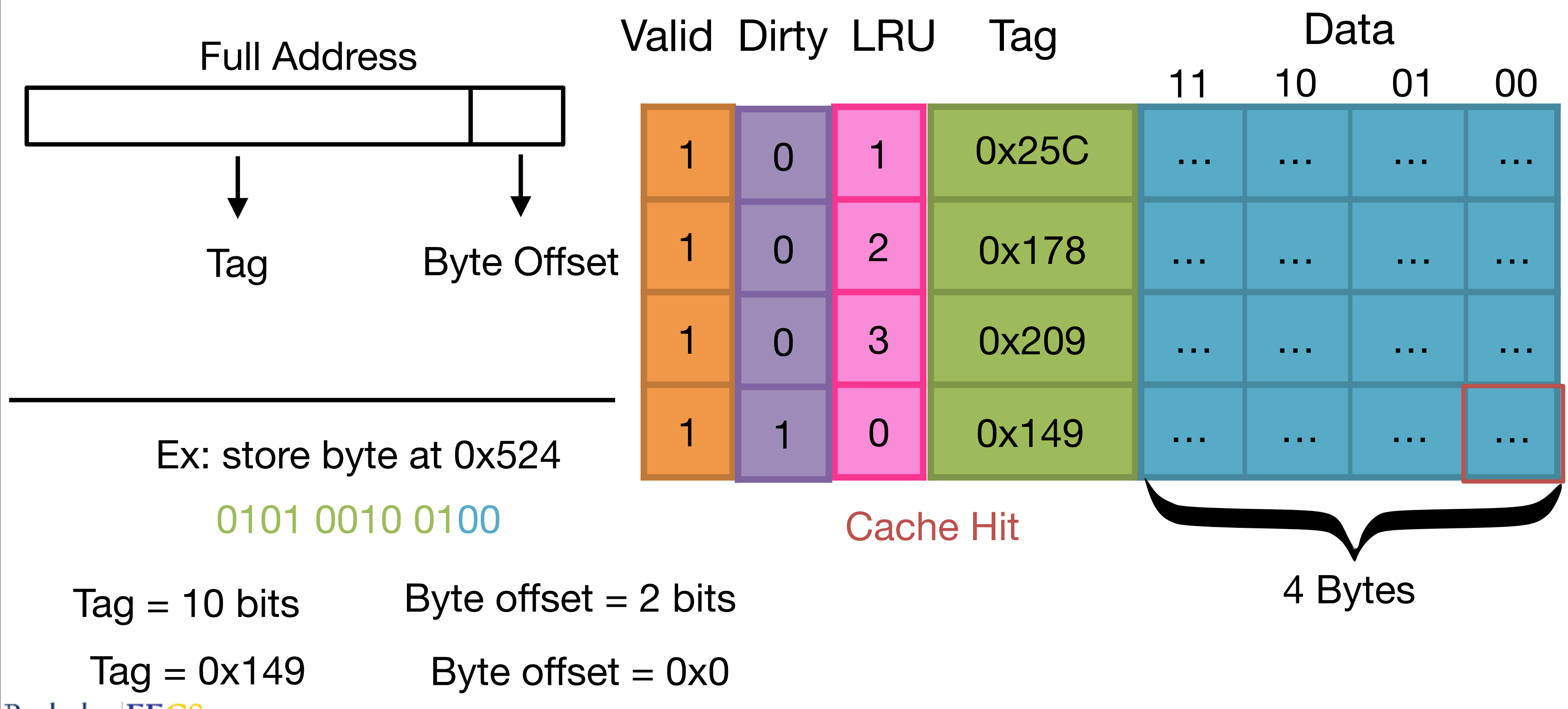
(1) 全相联缓存(Fully Associative Cache)¶

- 特点:数据可存放在任意缓存行,通过标签(Tag)匹配查找。
- Terminology:
- cache line / block: a single entry in the cache,能够从 memory 到 cache 的最小存储单元(典型的大小是 64 bytes)
- line / block size: number of bytes in each cache line (这里是 4 bytes,注意不要包括 tag 和 valid bit)
- tag: identifies the data stored at a given cache line
- valid bit: tells you if the data stored at a given cache line is valid
- Capacity: The total number of data bytes that can be stored in a cache (这里是 16 btyes)

- 地址结构:
- 例:12 位地址,4 字节块大小 → Tag 占 10 位,Offset 占 2 位。
- 工作流程:
- 命中:标签匹配 → 直接读取数据。
- 未命中:从内存加载整个块(即使只需 1 字节),替换旧块(如 LRU 策略)。
- 例:访问地址
0x5E0,若 Tag 匹配缓存行,则命中;否则加载整个块0x5E0-0x5E3。
- tags 在 cache 中可能会占用非常多的空间
- valid bit: 由于在程序启动时,之前的 cache 无效,所以需要一个 indicator 来指示 tag entry 是否对当前程序有效,于是在 cache tag entry 中加入一个 valid bit,
0表示 cache miss(即使是由于错误读取到 0),1表示 cache hit - Byte offset: 用 line size 计算,
# byte offset bits = log2(line size) - tag bits:
# tag bits = # address bits - # byte offset bits - 由于 locality,读取数据时,即使只需要读一个 byte 的数据,也要将整个 Line 的数据全部读取出来
- LRU (Least-Recent used): 硬件负责保存 access history,当 cache 满时,覆盖最久未使用过的数据
(2) 直接映射缓存(Direct Mapped Cache)¶

- 特点:每个内存块只能映射到唯一缓存行(通过索引 Index,也等价于对地址取模操作,如上图)。
- 地址结构:
- 例:12 位地址,4 行缓存 → Index 占 2 (\(\log_{2}4\)) 位,Tag 占 8 位,Offset 占 2 位。使用 write-through 策略

- 冲突问题:同一索引下的不同 Tag 导致频繁替换(miss 率高)。
- 例:地址
0xFE2和0xDF9映射到同一索引,导致相互覆盖。
- 例:地址
- 硬件实现:

(3) 组相联缓存(Set Associative Cache)¶

- 特点:折中方案,每组(Set)包含多个缓存行(如 2 路组相联)。
- 地址结构:
- 例:12 位地址,2 组 → Index 占 1 位,Tag 占 9 位,Offset 占 2 位。
- 优势:减少冲突,提升命中率。
- 例:组内可存多个 Tag,访问
0x8E8和0x8E9可能在同一组内命中。
(4) 对比¶


4. 缓存替换策略¶
- LRU(Least Recently Used):替换最久未使用的块,硬件维护保存顺序。
- 例:全相联缓存中,记录每行的访问时间,优先替换最旧的(这里 1、2、3、0 仅仅是编号,比方说可以是在最前面的是最近访问的)

- Approximate LRU (clock algo):由于 LRU 策略中每次都需要更新所有 entry,会非常耗费时间,所以采用
- 为每一个 cache line 添加一个 reference bit,当每次 access 一个 cache line 的时候,将对应的 reference bit 设置为 1
- 每当需要替换(eviction)时,从一个 entry 开始(循环)检查,遇到 1 则置换为 0,反之如果是 0 则替换掉这一 entry
- 类似于时钟,在一次替代后,将“时针”指向下一个 entry,便于下一次的指向
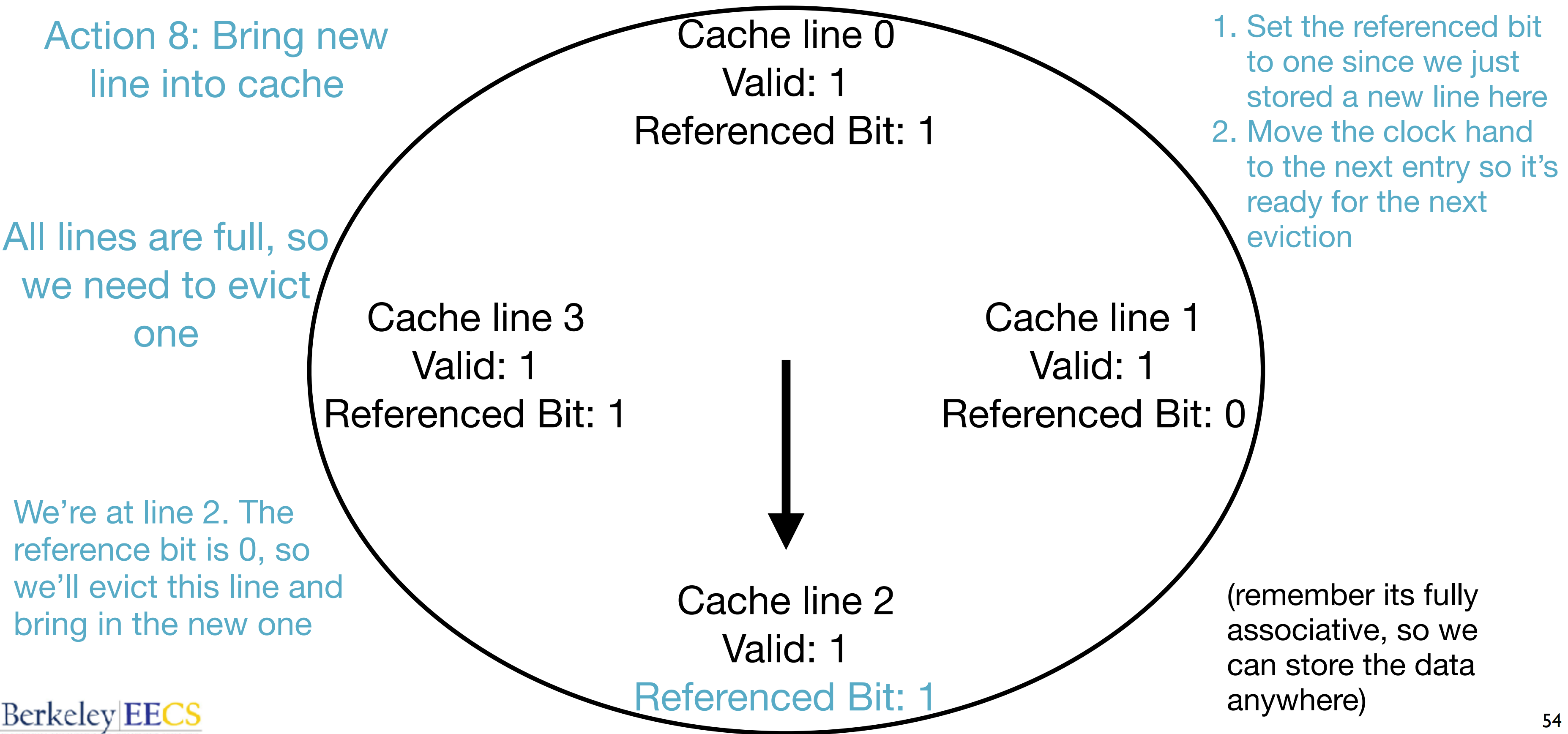
- 其他策略:most recent used,random
使用 approximate LRU 的 full associative cache:

5. 写策略¶
- 写直达(Write-Through):同时更新缓存和内存,简单但速度慢。
- 写回(Write-Back):仅更新缓存,标记为“脏”(Dirty Bit),替换时写回内存。
- 例:频繁修改同一数据时,写回策略减少内存访问次数。
- 写未命中策略
- Write allocate:当遇到 write miss 的时候,将 line 写入 cache 同时更新 memory 中的 line。通常搭配 write back
- 当 read / write miss,line 被加载入 cache
- 当 write hit,仅更新 cache,并设置 dirty bit 为 1
- No write allocate:仅更新 memory 中的 line,而不写入 cache。通常搭配 write through
- 当 write hits,更新 cache 和 memory
- 当 write miss,cache 不更新,memory 更新
- 当 read miss,再将 line 更新入 memory
- Write allocate:当遇到 write miss 的时候,将 line 写入 cache 同时更新 memory 中的 line。通常搭配 write back
6. 缓存性能优化¶
- 增大块大小:利用空间局部性,但可能加载无用数据。
- 多级缓存:L1(小且快)、L2(较大稍慢)、L3(更大更慢),层级化平衡速度与容量。

- 通过合理安排计算方式,可以通过缓存机制加速计算(如矩阵乘法等)
7. 缓存未命中类型¶
- Compulsory Miss: 第一次访问从未在 cache 中出现过的 block
- Capacity Miss: 缓存容量不足,导致数据被替换
- Conflict Miss: 在 set-associative or direct mapped caches 中,数据映射到同一索引,竞争导致替换
8. 缓存性能分析¶
Average Memory Access Time (AMAT): hit time + miss rate * miss penalty。在二级缓存中,