NCCL Collective Operations 笔记
约 2183 个字 62 行代码 5 张图片 预计阅读时间 12 分钟 共被读过 次
参考 Collective Operations — NCCL 2.25.1 documentation、Collective Communication Functions
使用了 GPT 辅助写作
1. 简介¶
NCCL (NVIDIA Collective Communications Library) 是一个为多 GPU 和多节点分布式训练设计的高效通信库,旨在解决大规模并行训练中的集体通信问题。NCCL 提供了多个高效的集体操作接口,可以在多 GPU 环境中处理通信任务,如数据的广播、聚合和全连接通信。
NCCL 支持的主要集体操作有:
- Broadcast:将数据从一个节点发送到所有其他节点。
- Reduce:将数据从多个节点合并到一个节点。
- All-Reduce:所有节点的数据都会与其他节点的数据进行合并,并返回给所有节点。
- All-Gather:每个节点将其数据发送给其他所有节点。
- Reduce-Scatter:将数据从所有节点合并后按均匀划分到每个节点。
- All-to-All:在所有节点之间交换数据。
2. NCCL 支持的集体操作¶
除此之外,还支持 P2P 操作,直接在 GPU 间进行通信。
2.1. Broadcast¶
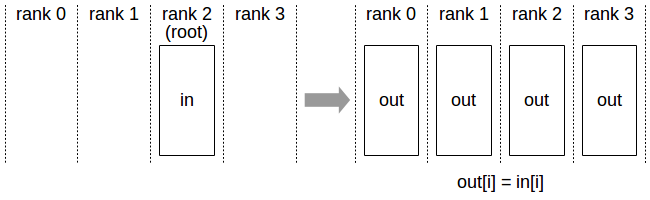
Broadcast 操作会将数据从一个源节点传送到所有其他节点。该操作通常用于将模型或数据从主节点广播到所有计算节点。
- 应用场景:参数初始化,模型同步。
- API:
ncclResult_t ncclBroadcast(void* sendbuff, void* recvbuff, int count, ncclDataType_t datatype, int root, ncclComm_t comm, cudaStream_t stream);
- 参数说明:
sendbuff:发送缓冲区的指针。只有根节点(root)会使用该缓冲区中的数据,其他节点的recvbuff会收到这个数据。recvbuff:接收缓冲区的指针。所有节点都将接收数据。count:数据元素的数量。datatype:数据类型,NCCL 支持多种数据类型,如ncclFloat,ncclInt32等。root:广播的源节点编号。只有这个节点的数据会被广播到其他节点。comm:通信器对象,管理 GPU 间的通信。stream:CUDA 流,指定在哪个流上执行操作。
- 返回值:
ncclSuccess:成功执行操作。ncclInternalError:内部错误,通常是通信失败。ncclInvalidArgument:传递给函数的参数无效。
- 用法示例:
ncclComm_t comm;
int rank = 0;
int size = 2;
int count = 1024;
float* sendbuff = (float*)malloc(count * sizeof(float));
float* recvbuff = (float*)malloc(count * sizeof(float));
// 初始化通信器
ncclCommInitRank(&comm, size, comm_id, rank);
// 执行广播操作
ncclBroadcast(sendbuff, recvbuff, count, ncclFloat, 0, comm, stream);
// 销毁通信器
ncclCommDestroy(comm);
- 执行过程:
- 只有
root节点的数据会被存储到sendbuff中。 - 所有其他节点通过
recvbuff接收从root节点广播的数据。
- 只有
2.2. Reduce¶
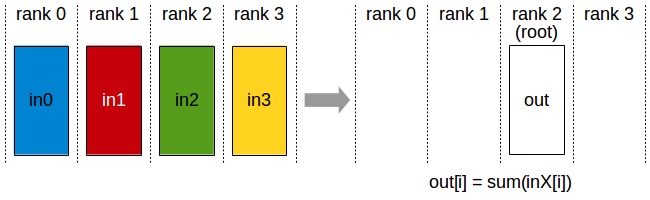
Reduce 操作将数据从多个节点合并到一个节点,合并操作基于某个二元操作(如加法、乘法等)。常见的聚合操作如梯度求和。
- 应用场景:在训练过程中合并各节点计算的梯度。
- API:
ncclResult_t ncclReduce(void* sendbuff, void* recvbuff, int count, ncclDataType_t datatype, ncclRedOp_t op, int root, ncclComm_t comm, cudaStream_t stream);
- 参数说明:
sendbuff:发送缓冲区的指针。recvbuff:接收缓冲区的指针。只有root节点会将结果存储在该缓冲区。count:数据元素的数量。datatype:数据类型。op:指定的合并操作,如加法(ncclSum)、乘法(ncclProd)等。root:指定哪个节点收集结果。comm:通信器对象,管理节点之间的通信。stream:CUDA 流,指定在哪个流上执行操作。
- 返回值:
ncclSuccess:成功执行操作。ncclInternalError:内部错误。ncclInvalidArgument:传递的参数无效。
- 用法示例:
ncclComm_t comm;
int rank = 0;
int size = 2;
int count = 1024;
float* sendbuff = (float*)malloc(count * sizeof(float));
float* recvbuff = (float*)malloc(count * sizeof(float));
// 初始化通信器
ncclCommInitRank(&comm, size, comm_id, rank);
// 执行归约操作(求和)
ncclReduce(sendbuff, recvbuff, count, ncclFloat, ncclSum, 0, comm, stream);
// 销毁通信器
ncclCommDestroy(comm);
2.3. All-Reduce¶
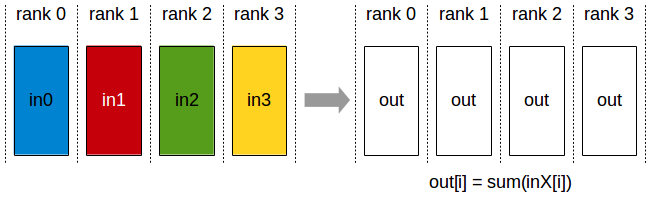
All-Reduce 操作在所有节点之间进行数据的归约操作,合并后的结果将返回给每个节点。通常用于训练过程中进行全局梯度更新。满足
- 应用场景:数据并行训练时同步各个 GPU 的梯度。
- API:
ncclResult_t ncclAllReduce(void* sendbuff, void* recvbuff, int count, ncclDataType_t datatype, ncclRedOp_t op, ncclComm_t comm, cudaStream_t stream);
- 参数说明:
sendbuff:发送缓冲区的指针。recvbuff:接收缓冲区的指针。每个节点都将接收合并后的数据。count:数据元素的数量。datatype:数据类型。op:指定的合并操作。comm:通信器对象,管理节点之间的通信。stream:CUDA 流,指定在哪个流上执行操作。
- 返回值:
ncclSuccess:成功执行操作。ncclInternalError:内部错误。ncclInvalidArgument:参数无效。
- 用法示例:
ncclComm_t comm;
int rank = 0;
int size = 2;
int count = 1024;
float* sendbuff = (float*)malloc(count * sizeof(float));
float* recvbuff = (float*)malloc(count * sizeof(float));
// 初始化通信器
ncclCommInitRank(&comm, size, comm_id, rank);
// 执行All-Reduce操作(求和)
ncclAllReduce(sendbuff, recvbuff, count, ncclFloat, ncclSum, comm, stream);
// 销毁通信器
ncclCommDestroy(comm);
2.4. All-Gather¶
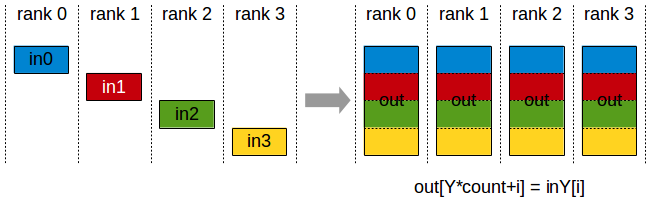
All-Gather 操作让每个节点将其数据发送给其他所有节点,每个节点会收集来自其他节点的数据。
- 应用场景:聚合各节点的部分结果,适用于分布式数据处理。
- API:
ncclResult_t ncclAllGather(void* sendbuff, void* recvbuff, int count, ncclDataType_t datatype, ncclComm_t comm, cudaStream_t stream);
2.5. Reduce-Scatter¶
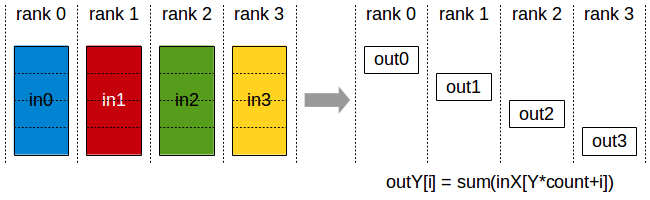
Reduce-Scatter 操作将所有节点的数据进行合并后,分散到各个节点。每个节点将接收到所有其他节点的数据的一个部分。
- 应用场景:分布式训练中的梯度计算和数据处理。
- API:
ncclResult_t ncclReduceScatter(void* sendbuff, void* recvbuff, int count, ncclDataType_t datatype, ncclRedOp_t op, ncclComm_t comm, cudaStream_t stream);
2.6. All-to-All¶
All-to-All 操作允许所有节点之间交换数据。每个节点都将其数据的一部分传递给其他节点,并接收其他节点的数据。
- 应用场景:多 GPU 并行训练时,需要大规模的数据交换。
- API:
ncclResult_t ncclAllToAll(void* sendbuff, void* recvbuff, int count, ncclDataType_t datatype, ncclComm_t comm, cudaStream_t stream);
3. NCCL 通信操作的基本特点¶
- 高效性:NCCL 针对多 GPU 和多节点的通信进行了高度优化,能够充分利用 GPU 和网络带宽。
- 并行性:NCCL 支持跨多个 GPU 并行执行集体操作,提高了效率。
- 跨平台支持:NCCL 支持在不同硬件架构上运行,包括单机多 GPU、分布式 GPU 集群等。
- 自动化优化:NCCL 会根据硬件特性(如 PCIe 拓扑结构、网络带宽等)自动优化通信路径。
4. 使用 NCCL 的基本步骤¶
4.1. 初始化¶
每个集体操作都需要一个通信器(ncclComm_t)来管理操作的过程。在多 GPU 的情况下,通信器负责协调 GPU 之间的通信。初始化通信器:
4.2. 执行通信操作¶
在初始化通信器后,可以调用对应的集体操作函数来执行通信任务。大部分操作函数都需要传入数据缓冲区、数据类型、操作类型、通信器等信息。
cpp ncclAllReduce(sendbuff, recvbuff, count, ncclFloat, ncclSum, comm, stream);
4.3. 销毁通信器¶
在通信完成后,释放通信器资源。
5. 性能优化¶
NCCL 提供了多种方式来优化性能:
- GPU 拓扑感知:NCCL 会根据 GPU 的拓扑结构自动选择最优的通信路径。
- 流控制:通过流控制和异步操作,减少通信延迟。
- 硬件加速:NCCL 能够利用 NVIDIA 的硬件加速(如 NVLink、InfiniBand)来提升性能。
6. CUDA 流¶
CUDA 流(Streams)是 CUDA 中用于控制操作异步执行的机制。一个流是一个操作的队列,CUDA 在流中顺序执行任务。多个流可以并行执行,且任务在流内是顺序的,但不同流中的任务可以并行执行。流的使用可以大大提升 GPU 计算的吞吐量,因为它允许 GPU 在执行计算任务的同时处理其他操作(如内存拷贝、内核执行等)。
6.1. 基本特性¶
- 顺序性:
- 同一个流中的操作会按顺序执行。即,流内的任务是顺序执行的。
- 并行性:
- 不同流中的任务是可以并行执行的(前提是流之间没有依赖关系)。例如,一个流执行计算任务,另一个流执行数据传输操作时,它们可以在同一时间并行执行。
- 异步执行:
- CUDA 流的主要功能是使得 GPU 上的任务可以异步执行,从而提升执行效率。比如,一个流在传输数据时,另一个流可以进行计算。
- 默认流:
- 如果没有显式指定流,CUDA 默认使用一个默认流(
0)。在默认流中,所有任务会按顺序执行,且默认流的任务与其他流中的任务是串行的。
- 如果没有显式指定流,CUDA 默认使用一个默认流(
6.2. 使用¶
- 创建流: 创建流可以通过
cudaStreamCreate或cudaStreamCreateWithFlags(设置流的某些特性)来完成。流在创建后可以传递给 CUDA 核函数、内存拷贝函数等。
- 内存拷贝与内核执行: 在使用流时,内存拷贝和内核执行操作可以与其他流中的任务并行执行。例如:
// 在流 stream 中执行内存拷贝和计算任务
cudaMemcpyAsync(d_dest, d_src, size, cudaMemcpyDeviceToDevice, stream);
kernel<<<blocks, threads, 0, stream>>>(d_data);
- 同步和流控制: 可以使用
cudaStreamSynchronize来同步流,确保流中的任务都执行完毕。例如,确保内存拷贝完成后再执行后续操作:
- 销毁流: 完成流的使用后,需要销毁流,释放资源:
在 NCCL 中,流主要用于以下方面:
- 异步执行通信操作: 使用流,NCCL 可以在后台执行集体通信操作,而不阻塞主计算流程。这样可以提高计算和通信的并行度,减少等待时间。
- 通过流控制执行顺序: 如果需要确保多个 NCCL 操作按顺序执行,可以将它们放在同一个流中。
- 与其他 CUDA 操作并行: NCCL 操作可以与 CUDA 内核或其他内存拷贝操作并行执行,从而提高计算吞吐量。例如,可以在一个流中执行通信操作,在另一个流中执行训练过程的计算任务。