LLM 笔记大杂烩
约 1928 个字 56 行代码 3 张图片 预计阅读时间 10 分钟 共被读过 次
施工中……
Attention¶
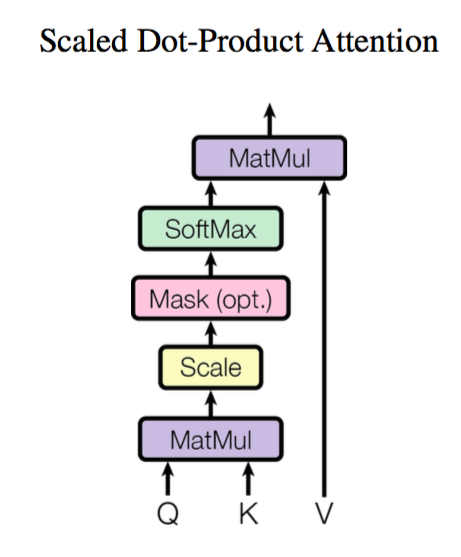
输入序列
通过可训练的权重矩阵 \(W^{Q}\in \mathbb{R}^{d_{1}\times d_{k}}\),得到 queries
然后对外来的(或者 \(X\) 自己的子序列)
通过 \(W^{K}\in \mathbb{R}^{d_{2}\times d_{k}}, W^{V}\in \mathbb{R}^{d_{2}\times d_{v}}\),有 keys 和 values
之后
可以认为是将一个 \(n\times d_{k}\) 的序列 \(Q\) 转化为了新的序列 \(K\in \mathbb{R}^{n\times d_{v}}\)
逐向量版本
Multi-head Attention¶
也就是将 \(Q\)、\(K\)、\(V\) 按照第二个维度拆分后,分别进行计算,然后拼接起来
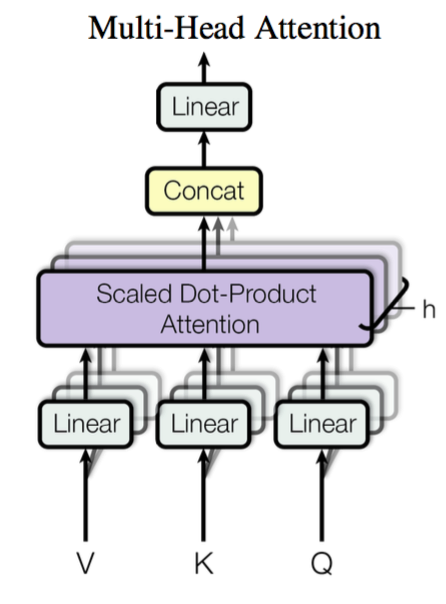
这里 \(W_{i}^{Q},W_{i}^{K}\in \mathbb{R}^{d_{k}\times \bar{d}_{k}}, W_{i}^{V}\in \mathbb{R}^{d_{v}\times \bar{d}_{v}}\)
之后
Self-Attention¶
只需要将 \(Q\)、\(K\)、\(V\) 都使用一个序列 \(X\) 得到即可
之后得到多头注意力
拼接后得到
可以取 \(d_{v}\) 和 \(X\) 序列的每一个向量维度(即 \(X\) 的第二维度)相同
Linear Attention¶
在最原始的 attention 中,计算复杂度是 \(O(n^{2})\),主要是由 softmax 引起的,更一般的,attention 公式可以写作
其中相似度函数 \(\text{sim}\) 需要满足非负性,也因此无法简单的去除原式中的 softmax 以加快矩阵运算 \((n\times d_{k})\times(d_{k}\times m)\times(m\times d_{v})\)
核函数形式¶
将 \(q_{i},k_{j}\) 用核函数映射到非负区域上,从而保证非负,即
利用 Softmax 特殊性质¶
只要先对 \(Q\) 的 \(d\) 那一维和 \(K\) 的 \(n\) 那一维进行 softmax,那么得到的结果自动满足归一化条件:
Grouped Query Attention¶
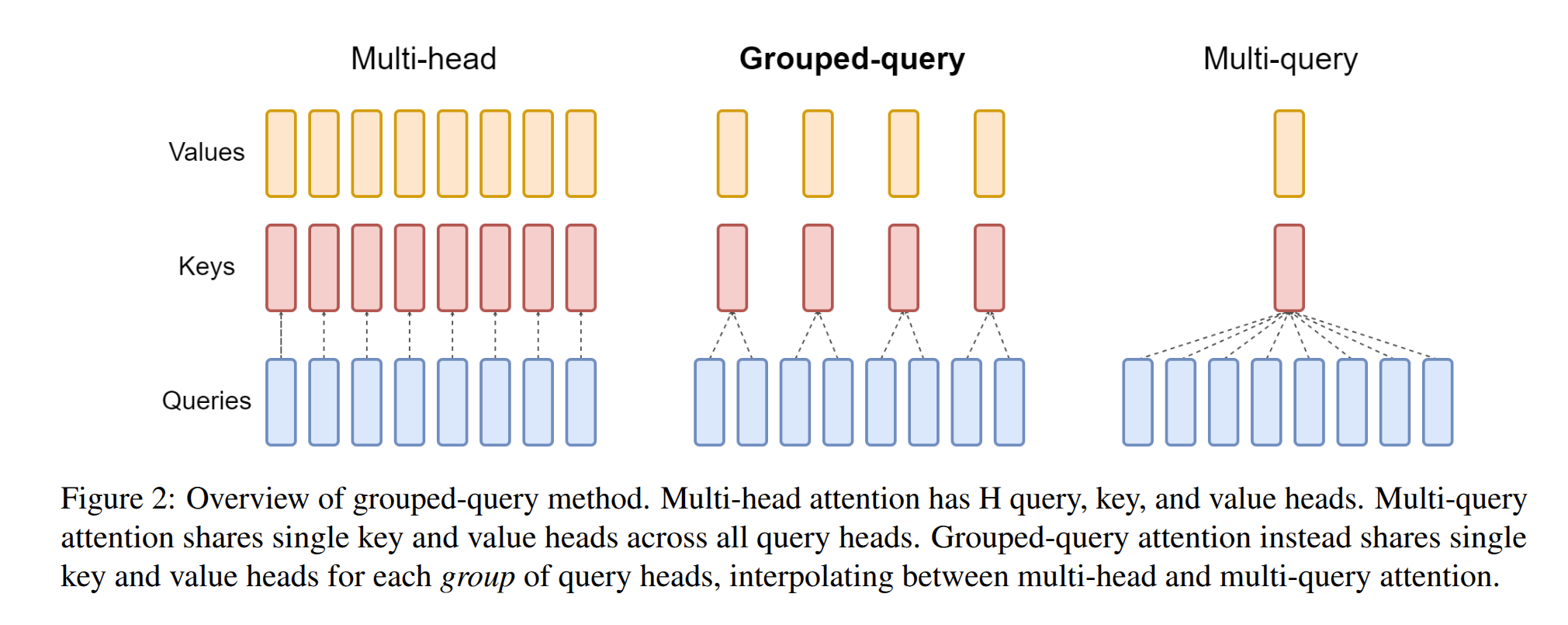
Queries heads 被分为了若干个组,每个组内共享同一个 key head 和 value head。划分组的方法:
- Grouping queries based on similarity: computing a similarity metric between queries and then assigning them to groups accordingly.
- Dividing query heads into groups: query heads are divided into groups, each of which shares a single key head and value head.
- Using an intermediate number of key-value heads
- Repeating key-value pairs for computational efficiency: key-value pairs are repeated to optimize performance while maintaining quality
优点:
- Interpolation 减少了 MHA 和 MQA 中 quality degradation、training instability 等问题
- Efficiency 通过选择恰当的 key-value heads 组数,提高效率的同时保持了质量
- Trade-off 在 MHA 和 MQA 中保证了质量
Position Embedding¶
为了表征 token 的相对位置,可以引入位置编码,否则 transformer 将无法辨认词语间的先后关系。
Sinusoidal¶
Google 的原始论文中给出的编码为
其中 \(P\) 为序列总长度。之所以使用这个表达式,是为了便于表征相对位置,因为有
即第 \(p+k\) 位的表征可以由第 \(p\) 位的表征加上 \(k\) 位的偏移得到
RoPE¶
为了实现使用绝对位置编码的方式实现相对位置编码,经过推导(见 reference 3),得到对二维向量 \(\vec{q}\),在 \(m\) 处的位置编码为
即对应向量 \(\vec{q}\) 旋转 \(m\theta\) 的角度。对于任意偶数维的 RoPE,可表示为二维情形的拼接,即
对于 query \(q\) 和 key \(k\),分别乘上旋转矩阵 \(\mathcal{R}_{m}\) 和 \(\mathcal{R}_{n}\) 就相当于:
又由于 \(\mathcal{R}_{m}\) 的稀疏性,不使用矩阵乘法,而是用
可以看出 RoPE 是“乘性”的位置编码,而 sinusoidal 是“加性”的。
RoPE 还是目前唯一一种可以用于 Linear Attention 的相对位置编码。
二维情形¶
上面是在 NLP 中的应用,如果想推广到图像等二维数据中,可以推广为
即将输入向量分为两半,一半使用一维的 x-RoPE,一半使用一维的 y-RoPE。并且由于这个矩阵是正交的,在给定 \(\mathcal{R}_{x,y}\) 后可以反解出 \(x\) 和 \(y\)。
代码实现¶
# 照搬 llama 的源码,写了点注释
import torch
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
# *xq.shape[:-1]: 将第 0 维到倒数第 2 维保留,最后一维两两配对,并视作复数
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_) # 便于广播的辅助han
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3) # 元素间相乘,然后从第三维(head_dim 那维)开始拉平,即将之前的两两配对视为复数展开为实数
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
而 freqs_cis 按照论文的实现为:
freqs_cis 实现
import torch
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
"""
Precompute the frequency tensor for complex exponentials (cis) with given dimensions.
This function calculates a frequency tensor with complex exponentials using the given dimension 'dim'
and the end index 'end'. The 'theta' parameter scales the frequencies.
The returned tensor contains complex values in complex64 data type.
Args:
dim (int): Dimension of the frequency tensor.
end (int): End index for precomputing frequencies.
theta (float, optional): Scaling factor for frequency computation. Defaults to 10000.0 (论文中的默认值).
Returns:
torch.Tensor: Precomputed frequency tensor with complex exponentials.
"""
# Calculate the frequency scaling factors for the dimension.
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
# Create a tensor of integers from 0 to 'end - 1' on the same device as 'freqs'.
t = torch.arange(end, device=freqs.device) # type: ignore
# Compute the outer product of 't' and 'freqs' to get the frequency matrix.
freqs = torch.outer(t, freqs).float() # type: ignore
# Convert the frequency matrix to a complex tensor using polar coordinates.
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64, 用复数表示
# Return the complex frequency tensor.
return freqs_cis
Normalization¶
RMSNorm¶
相比 LayerNorm,RMSNorm 没有减去均值的步骤,而是直接除以均方根:
其中 \(\gamma\) 为超参数(也可以被训练);\(\epsilon\) 是为了防止 \(\text{RMS}(x)=0\)
用 RMSNorm 替代 LayerNorm 的可能原因为:
- 计算效率更高
- 超参数更少
- 研究表明,减去均值(均匀化)对模型性能影响有限,而缩放操作(rescaling)影响更大
- 硬件友好:无须计算均值,便于并行化
代码实现
import torch.nn as nn
import torch
class RMSNorm(nn.Module):
def __init__(self, dim, eps=1e-5):
super().__init__()
self.gamma = nn.Parameter(torch.ones(dim))
self.eps = eps
def forward(self, x: torch.Tensor):
rms = torch.rsqrt(x.pow(2).mean(-1, keepdim=True).sqrt() + self.eps)
x_hat = x / rms
out = self.gamma * x_hat
return out
Reference¶
- 《Attention is All You Need》浅读(简介+代码) - 科学空间|Scientific Spaces
- 线性Attention的探索:Attention必须有个Softmax吗? - 科学空间|Scientific Spaces
- Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
- 75、Llama源码讲解之RoPE旋转位置编码
- GitHub - meta-llama/llama: Inference code for Llama models
- Multi-Query Attention Explained. Multi-Query Attention (MQA) is a type… | by Florian June | Towards AI
- What is Grouped Query Attention (GQA)?
- GitHub - fkodom/grouped-query-attention-pytorch: (Unofficial) PyTorch implementation of grouped-query attention (GQA) from "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints" (https://arxiv.org/pdf/2305.13245.pdf)
- 和 deepseek 的问答